
Welcome to the last part of this Blog series. Here are the links to part 1 and part 2

Implementing Machine Learning for Malware Detection
Now, having sifted through the wealth of system calls and identified our crucial data points, we find ourselves at an interesting juncture. The question that presents itself is — how do we use this data to detect malware? Well, it’s time to put the power of machine learning to work and create a model to achieve this task.
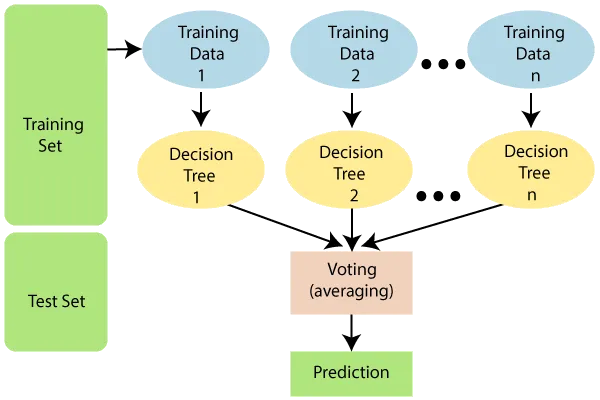
Let’s take a step-by-step walkthrough this process
- Create Training and Test Dataset: Our first step is to divide our data into a training set and a test set. This is akin to separating our data into a learning phase and a testing phase for our model.
- Select Random Data Points: From our training set, we randomly select a number of data points. This ensures our model’s learning isn’t biased and it can make accurate predictions with unseen data.
- Build a Decision Tree: Next, we build a decision tree using these selected data points. Imagine this as creating a flowchart that helps the model make decisions based on certain conditions.
- Choose Number of Decision Trees: We then decide on the number of decision trees that our model should have. This essentially means we’re deciding how many ‘thinking paths’ our model should consider.
- Repeat Steps 1 & 2: As part of refining the model, we repeat the process of creating datasets and selecting random data points.
- Predict and Assign Categories: Finally, for our test data points, we run them through each decision tree to get their predictions. We then assign these data points to the category that receives the most votes across all decision trees.

Please note that we built our own classification model by combining multiple pseudocodes from different existing algorithms. Therefore, we are neither disclosing the code nor the method (Maybe in future Blog, I will share how I did it). However, the purpose here is to understand the broader approach of using machine learning in malware detection. If you can grasp this concept, you’re on the right track to understanding this fascinating field of study.
Classification, Training, and Prediction: Bringing Our Model to Life
In the realm of machine learning, training a model is key to achieving accurate predictions. Using our established datasets, we train our model on system call names, frequencies, and their association with either legitimate applications or malware.
This allows the model to identify and evaluate which system calls are crucial for accurate predictions. It can then filter and categorize applications based on these vital system calls. For example, if a particular system call only appears during the execution of malware, its occurrence can indicate a potential threat.
Once the model has been trained, it can then predict whether a file is malicious based on its test dataset results.
Let’s take a moment to review our training datasets, which you will find detailed in the following image. These datasets comprise three key elements: the application’s name, the specific system call, and the frequency at which this system call occurs. To support our understanding and categorization efforts, we have labelled them as “G” for legitimate app, and “M” for Malware. This classification will aid in differentiating the nature of system call behaviors across various application types.

Below set of data are for testing purpose without categorization or labeling

Streamlining System Calls
Next, our task is to identify and evaluate the essential system calls that can assure us optimal accuracy. As illustrated in the subsequent image, applications have been categorized based on the system call, with ‘0’ denoting a legitimate application and ‘1’ representing malware. For instance, the “NtClose” system call appears in both legitimate application and malware. In such cases, determining whether the application is malware, or a legitimate application purely based on the “NtClose” system call can be a challenging feat.

Moving forward, let’s examine another system call, as depicted in the following image. Here, we observe that the frequency of the “NtIsUILanguageCommitted” system call is zero for legitimate applications. This indicates that legitimate system applications are not invoking the “NtIsUILanguageCommitted” system call during their execution. On the contrary, malware applications do call this particular system call.

As depicted in the following figure, we see that the top two features are notably informative. These features, due to their high ranking, play a more significant role. Particularly, the two features named “NtQuerySymbolicLinkObject” and “NtIsUILanguageCommitted” have a profound influence on the model and its overall performance.

Assessing Test Data Predictions and Model Accuracy
Now that our model has been trained, it’s time to put it to the test and evaluate its predictive power. To do this, a new prediction vector was created, as illustrated below.
Despite one slight misstep — a malware instance was incorrectly classified as a legitimate application — our model displayed an impressive score of 1.0, indicating 100% accuracy.